

















































There are ongoing discussions from high-level expert groups from the EU Commission about what regulation of Artificial Intelligence – particularly the algorithms that process data – will look like. There is a high priority to not only create alignment with the GDPR but to add flexibility for future advancements so that a baseline level of data protection is always provided, even as new AI applications are implemented.
There are many elements of the GDPR that are particularly worth looking closer at regarding algorithmic models for recommendations, predictions, and decisions.
Labeling AI systems according to the risk they pose
Article 22 of GDPR speaks to a data subject’s right to be exempt from decisions that are wholly made with automated processing. A precursor to this right is that a data subject must know if a decision is powered only by automated processing before they can request to be exempt. Labeling automated processing systems is the solution that many companies use to address this, and many working groups call for widespread labeling of AI systems and propose it for upcoming EU regulation.
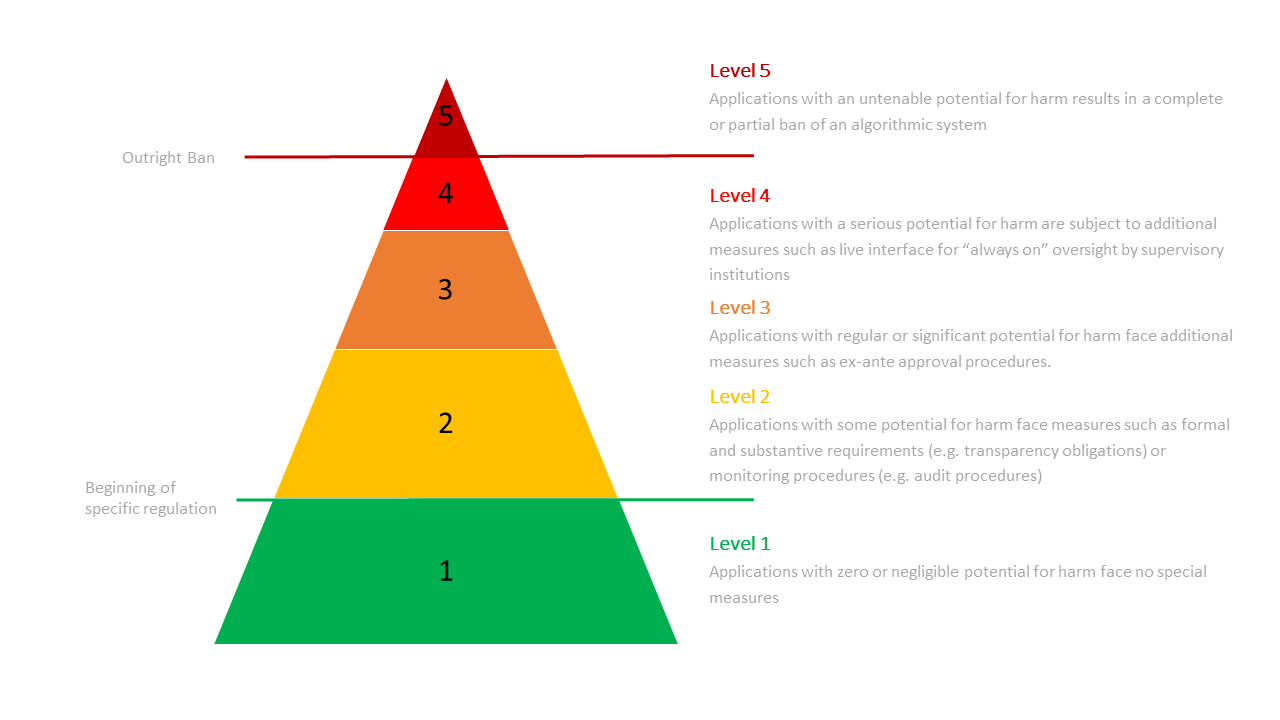
One option was proposed by the German Data Ethics Commission and is a five-level risk-based system for AI regulation. It assumes that there is a gradient of how much harm an algorithm could potentially cause and lays out increasingly strict requirements and interventions accordingly. The AI system’s potential to cause harm would be calculated by the likelihood and severity of that harm. The level of risk assigned to a system would impact the requirements of corrective and oversight mechanisms, specifications regarding the transparency of algorithmic systems and the explainability and comprehensibility of the results, and rules on the assignment of responsibility and liability within the context of the development and use of algorithmic systems.
A regulation that follows this framework would define five levels of risk that an AI system could have, and among other safeguards would apply a label that corresponds with the level of risk the system poses. This figure is from the Opinion of the Data Ethics Commission report published in January 2020, outlining the five levels of risk and potential requirements that a system in each risk category would need to comply with.
Local explainability
The right to an algorithmic explanation in the GDPR has been heavily debated on what exactly that entails, and even if an explanation is required at all, leaving obvious gaps in the ability of the GDPR to assure protection to data subjects on this topic. The existence of this debate makes it almost certain that a clause on explainability in upcoming AI regulation will be included.
This of course means that regulators and eventually companies using AI will have to confront the paradox that while nearly every proposed framework for AI governance requires explainability, many algorithms do not have a satisfactory means of providing local, or individual, explanations. And even one of the front-runner solutions that determines the smallest change to input values that would deliver the desired outcome – first seen in LIME, sometimes called “contrastive explanations” by IBM and “counterfactual explanations” in the academic community – is rejected by the German Data Ethics Commission. They do not consider it a suitable option for local explanations because it doesn’t offer the user a complete picture of what affected the decision and may give the impression that some attributes are more influential than others when that is not the case.
What to expect
Regulation on the application of AI is still a long way from being finalized. But the EU will likely be among the first to provide legally binding guidance. We can expect more flexible phrasing than in the GDPR to address how quickly it has proved inadequate in governing data protection for AI and facial recognition applications. The risk-based framework is one option that would bring flexibility and allow for ongoing innovation but will cause interpretability issues and may leave huge numbers of algorithms unregulated – for example, all that falls under the level 1 risk.
Explainability may be regulated very harshly and may become an even larger barrier to maturity for machine and deep learning models than before. When there is a clear rejection of a specific explainability method by organizations that will likely influence the design of AI regulation, we can expect requirements that may not be technically possible yet, which would trigger a retraction of some solutions already on the market.
And we can expect AI regulation to be made in the model of the GDPR, using similar terminology and striving to fill the gaps in data protection that have been exposed since its implementation in 2018. One example is that we will likely see the terms “data controller” and “data processor” again, updated to fit the context of AI development and implementation. Another is that the “conditions for consent” will likely reappear in reference to populating training data sets and when the model is being implemented.
Legally binding regulation for AI is still on the distant horizon. The EU Commission is still finalizing its recommended framework for AI governance, a project two years in the making. Its next update was expected in June 2020. A regulation built on that framework will likely still take a few years to be approved.
For more information on the explainability of AI algorithms and topics related to the GDPR, check out our Leadership Brief on Explainable AI and the Advisory Note on Maturity Level Matrix for GDPR Readiness.
