

















































The Information Protection Life Cycle (IPLC) and Framework describes the phases, methods, and controls associated with the protection of information. Though other IT and cybersecurity frameworks exist, none specifically focus on the protection of information across its use life. The IPLC documents 3 stages in the life of information and 6 categories of controls which can be applied as controls to secure information.
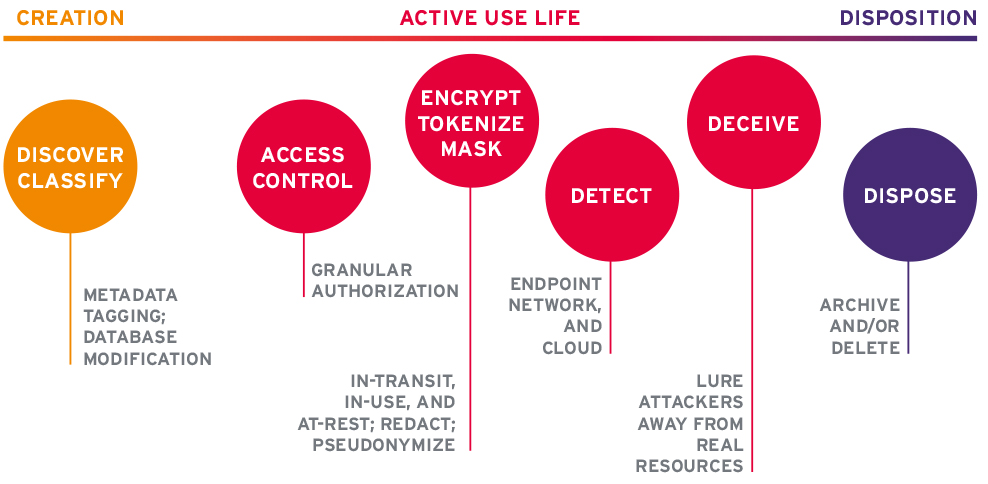
Stages in the life of information
Information is created, used, and (sometimes) disposed of when it is no longer needed or valid. Information can be actively created, such as when you start a new document, add records to a database, take photos, post blogs, etc. Information is also passively created when users and devices digitally interact with one another and with applications. Passively generated information often takes the form of log files, telemetry, or records added to databases without the explicit action of users. During its use life, information can be analyzed and modified in various ways by users, devices, and applications. After a certain point, information may cease to be useful, perhaps due to inaccuracies, inconsistencies, migrations to new platforms, incompatibility with new systems, and/or the regulatory mandates to store it has passed. When information is no longer useful, it needs to be disposed of by archival or deletion, depending on the case.
The types of controls applicable to information protection at each phase are briefly described below.
Discovery and classification
To properly protect information, it must be discovered and classified. The company picnic announcement is not as sensitive and valuable as the secret sauce in your company’s flagship product. Information can be discovered and classified at the time of creation and a result of data inventories. Thanks to GDPR’s Data Protection Impact Assessments (DPIAs), such inventories are more commonly being conducted.
Classification schemes depend on the industry, regulatory regimes, types of information, and a host of other factors. Classification mechanisms depend on the format. For structured data in databases, tools may add rows/columns/tables for tracking cell-level sensitivity. For unstructured data such as documents in file systems, metadata can be applied (“tagged”) to individual data objects.
Access Control
Access to information must be granular, meaning only authorized users on trusted devices should be able to read, modify, or delete it. Access control systems can evaluate attributes about users, devices, and resources in accordance with pre-defined policies. Several access control standards, tools, and token formats exist. Access control can be difficult to implement across an enterprise due to the disparate kinds of systems involved, from on-premise to mobile to IaaS to SaaS apps. It is still on the frontier of identity management and cybersecurity.
Encryption, Masking, and Tokenization
These are controls that can protect confidentiality and integrity of information in-transit and at-rest. Encryption tools are widely available but can be hard to deploy and manage. Interoperability is often a problem.
Masking means irreversible substitution or redaction in many cases. For personally identifiable information (PII), pseudonymization is often employed to allow access to underlying information while preserving privacy. In the financial space, vaulted and vaultless tokenization are techniques that essentially issue privacy-respecting tokens in place of personal data. This enables one party to the transaction to assume and manage the risk while allowing other parties to not have to store and process PII or payment instrument information.
Detection
Sometimes attackers get past other security controls. It is necessary to put tools in place that can detect signs of nefarious activities at the endpoint, server, and network layers. On the endpoint level, all users should be running current Endpoint Protection (EPP, or anti-malware) products. Some organizations may benefit from EDR (Endpoint Detection & Response) agents. Servers should be outfitted similarly as well as dump event logs to SIEMs (Security Incident and Event Management). For networks, some organizations have used Intrusion Detection Systems (IDS), which are primarily rule-based and prone to false positives. Next generation Network Threat Detection & Response (NTDR) tools have advantages in that they utilize machine learning (ML) algorithms to baseline network activities to be able to better alert on anomalous behavior. Each type of solution has pros and cons, and they all require knowledgeable and experienced analysts to run them effectively.
Deception
This is a newer approach to information protection, derived from the old notion of honeypots. Distributed Deception Platforms (DDPs) deploy virtual resources designed to look attractive to attackers to lure them away from your valuable assets and into the deception environment for the purposes of containment, faster detection, and examination of attacker TTPs (Tools, Techniques, and Procedures). DDPs help reduce MTTR (Mean Time To Respond) and provide an advantage to defenders. DDPs are also increasingly needed in enterprises with IoT and medical devices, as they are facing more attacks and the devices in those environments usually cannot run other security tools.
Disposition
When information is no longer valid and does not need to be retained for legal purposes, it should be removed from active systems. This may include archival or deletion, depending on the circumstances. The principle of data minimization is a good business practice to limit liability.
Conclusions
KuppingerCole will further develop the IPLC concept and publish additional research on the subject in the months ahead. Stay tuned! In the meantime, we have a wealth of research on EPP and EDR, access control systems, and data classification tools at KC PLUS.